I originally created this post and observed some rather embarrassing sloppiness and miscalculations. I’ve simply decided to pull the post and rework it. This is the result of those labors.
Recently, I answered a question on dba.stackexchange related to an interesting occurrence with incremental statistics. This led to an good conversation about the efficacy (and utility) of incremental statistics. The primary focus was on Erin Stellato’s confirmation that partition-level stats are not used by the Query Optimizer, thereby identifying a rather sizable gap in the utility of incremental statistics. The only possible benefit I could champion for incremental statistics was that it might allow us to sample at consistently higher rates since the entire table would not need to be sampled – just the ones that presented a compelling enough reason for update (modification counter being a primary focus). Naturally, we’d incur the penalty of the higher sample rate at the initial sampling, but ongoing maintenance would be able to support the higher sample rates because we would only have to sample at the partition level. In this scenario, there are two measures to consider:
- What’s the break-even point for the benefits partition-level sampling after having incurred the initial cost of the higher sample rate?
- Is it really even worth it? How do our query plans reflect the benefit?
For the sake of post length, let’s focus on the first question, as two variants. First, what is the break-even point for a “traditional” statistics object and an incremental statistics object at the same sample rate? Following that, if we can get higher sample rates at diminished times, what are the break-even points for these sample rates?
Breaking Even On The Same Sample Rate?
I’ve loaded the most recent StackExchange dump (everything except StackOverflow) and will evaluating the PostHistory table, with 21,637,283 rows. To baseline the process, I wanted to get a sense for the default sample rate on the table. 0.786988828495703% (yes, that was multiplied by 100 and it really is .79%).
-- PostHistory DDL
CREATE TABLE [dbo].[PostHistory](
[Id] [bigint] NOT NULL,
[PostHistoryTypeId] [int] NOT NULL,
[PostId] [bigint] NOT NULL,
[RevisionGUID] [uniqueidentifier] NOT NULL,
[CreationDate] [datetime2](3) DEFAULT '1900-01-01',
[UserId] [bigint] NULL,
[UserDisplayName] [nvarchar](500) NULL,
[Comment] [nvarchar](4000) NULL,
[Text] [nvarchar](max) NULL,
[CloseReasonId] [int] NULL,
[SiteId] [int] NOT NULL,
CONSTRAINT [pk_PostHistory] PRIMARY KEY CLUSTERED
(
[PostId] ASC,
[SiteId] ASC,
[PostHistoryTypeId] ASC,
[Id] ASC,
[CreationDate] ASC
)WITH (DATA_COMPRESSION = PAGE) ON [PRIMARY]
) ON [PRIMARY]
dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = off; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 1515 ms, elapsed time = 12359 ms. dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = on; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 1781 ms, elapsed time = 12674 ms.
We generally eschew default sample rates lower than 1% in our environments and prefer round up, so let’s get that timing for a 1% sample rate.
dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = off, sample 1 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 2000 ms, elapsed time = 14844 ms. dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = on, sample 1 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 2391 ms, elapsed time = 15646 ms.
So it looks like converting/updating a statistics object as incremental is marginally slower than a non-incremental statistic. I’ve not traced through this using windbg so I can’t speak with certainty as to why this occurs, but my suspicion is that is has to do with merging the stats pages. So what about subsequent full updates?
dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = off, sample 1 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 1829 ms, elapsed time = 13355 ms. dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with resample; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 2359 ms, elapsed time = 13272 ms. dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = on, sample 1 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 1907 ms, elapsed time = 13726 ms. dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with resample; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 1875 ms, elapsed time = 13475 ms.
The timings are consistent, so there doesn’t seem to be much overhead when moving between an incremental statistic and an non-incremental statistic.
With that information in hand, we can now set about the task of leveraging incremental statistics to reduce our statistics maintenance time. Updating each of the partitions, individually, at a 1 percent sample rate, produced the following results:
-- partition 1 --SQL Server Execution Times: -- CPU time = 0 ms, elapsed time = 7 ms. -- partition 2 --SQL Server Execution Times: -- CPU time = 16 ms, elapsed time = 23 ms. -- partition 3 --SQL Server Execution Times: -- CPU time = 78 ms, elapsed time = 550 ms. -- partition 4 --SQL Server Execution Times: -- CPU time = 63 ms, elapsed time = 856 ms. -- partition 5 --SQL Server Execution Times: -- CPU time = 188 ms, elapsed time = 2003 ms. -- partition 6 --SQL Server Execution Times: -- CPU time = 390 ms, elapsed time = 2682 ms. -- partition 7 --SQL Server Execution Times: -- CPU time = 453 ms, elapsed time = 2786 ms. -- partition 8 --SQL Server Execution Times: -- CPU time = 593 ms, elapsed time = 4248 ms. -- partition 9 --SQL Server Execution Times: -- CPU time = 375 ms, elapsed time = 1916 m
Obviously, there are some outliers here. Partitions 1-4 have extremely low timings, with Partition 1 containing 0 rows. Partition 7 is our largest partition with 5,855,947 rows, while Partition 8 is the slowest partition to update, but only has the third highest row count. (Sidebar: Interestingly, the sample rates for each of these partition varies at the row count level (see below). Perhaps Partition 8 is slower because of its higher sample rate, relative to the rest of the partitions. Keep in mind that a sample rate specifies the percentage of pages and we’re calculating the number of rows sampled. As such, Partition 8 looks to have a higher number of rows per page than other partitions. )
select
sysdatetime(),
schema_name = sh.name,
table_name = t.name,
stat_name = s.name,
index_name = i.name,
sample_rate = (100.*sp.rows_sampled) / sp.unfiltered_rows,
leading_column = index_col(quotename(sh.name)+'.'+quotename(t.name),s.stats_id,1),
s.stats_id,
parition_number = isnull(sp.partition_number,1),
s.has_filter,
s.is_incremental,
s.auto_created,
sp.last_updated,
sp.rows,
sp.rows_sampled,
sp.unfiltered_rows,
modification_counter = coalesce(sp.modification_counter, n1.modification_counter)
from sys.stats s
join sys.tables t
on s.object_id = t.object_id
join sys.schemas sh
on t.schema_id = sh.schema_id
left join sys.indexes i
on s.object_id = i.object_id
and s.name = i.name
cross apply sys.dm_db_stats_properties_internal(s.object_id, s.stats_id) sp
outer apply sys.dm_db_stats_properties_internal(s.object_id, s.stats_id) n1
where n1.node_id = 1
and (
(is_incremental = 0)
or
(is_incremental = 1 and sp.partition_number is not null)
)
and s.name = 'pk_PostHistory'
order by s.stats_id,isnull(sp.partition_number,1)
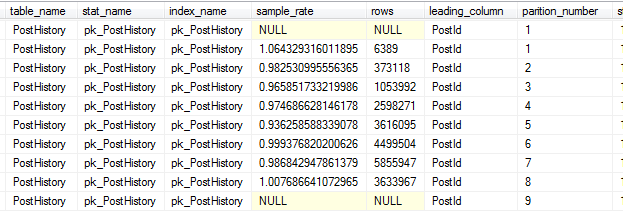
Let’s consider Partitions 5-9 as the partitions that we’d be most likely to take updates, or at least a more representative sample of update timing. The average of the update timings (for a 1 percent sample rate) for these 5 partitions is 2727 ms. Let’s extrapolate out the update timings and the point at which we’d realize the maintenance gains of incremental statistics. For the purposes of this calculation, I’m using the first timing of the 1 percent sampling.
| Update Occurrence | Non-Incremental | Incremental |
|---|---|---|
| 1 | 14844 | 15646 |
| 2 | 29688 | 18373 |
| 3 | 44532 | 21100 |
| 4 | 59376 | 23827 |
| 5 | 74220 | 26554 |
With sample rate being held constant, we can generalize that we begin to realize the maintenance benefit of incremental statistics as of the second occurrence. This is a nice fabricated situation, but what happens when an auto_stats update occurs? How long does it take? Does it just update the partition? Does it preserve sample rate?
I’ve dumped Partition 9’s data to a staging table. Once the data was effectively “backed up” to a different table, I deleted that data, inserted it back into the table, ran a select, and captured what happened with the auto_stats extended event on a SELECT that would fire the event. We see that the sample rate is preserved at 1 percent, and only the relevant partition is updated (I ensured I didn’t confuse myself by running this auto update-inducing query a few hours after the data modifications). We can also see that it took 397065 microseconds, but what’s not shown is that there were other stats updates that took upwards of 28534404 microseconds (~28.5 seconds). {A future research consideration would be to determine why it’s so much faster. My initial suspicion is that the pages were already read into memory and, as such, more rapidly sampled}

So even if we hit the auto_stats update threshold, we’re only going to resample the affected partition. If we affect multiple partitions with modifications that would fire an auto_stats event, we do see that just the affected partitions are updated.

So not only does a robust statistics maintenance plan offer maintenance window savings, the auto_stats resampling would also present additional benefit. This benefit would be noticed in the statistics updates that occur at any query plan (re)compilation that uses those statistics, potentially leading to a marginally faster query execution time due to lower resample times. Keep in mind that the effects of this would be observed more directly when AUTO_UPDATE_STATISTICS_ASYNC = OFF (default) is set on the database.
Can I Recover Time Lost From Choosing A Higher Sample Rate?
One of the premises I initially held in support of incremental statistics was that I could get away with a higher sample rate and eventually recover the time “lost” as a result of sampling the incremental statistic at a higher rate.
Because today is a new day, and I’m running these tests on a VM, I’d like to account for factors such as noisy neighbors so I’m going to re-baseline the 1 percent sampling on a non-incremental statistic.
dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = off, sample 1 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 2125 ms, elapsed time = 24571 ms.
Let’s evaluate for a test of 10 percent sampling on an incremental statistics object.
dbcc dropcleanbuffers; go set statistics time on; go update statistics dbo.PostHistory(pk_PostHistory) with incremental = on, sample 10 percent; go set statistics time off; go -- SQL Server Execution Times: -- CPU time = 15266 ms, elapsed time = 73439 ms.
I once again took the average of updates to Partitions 5-9 which came out to 18182 ms. Using this data, I projected how long it would take to recover the amount of time it took to sample at the higer rate (~73 seconds).
| Update Occurrence | Non-Incremental | Incremental |
|---|---|---|
| 1 | 73439 | 24571 |
| 2 | 91621 | 49142 |
| 3 | 109803 | 73713 |
| 4 | 127985 | 98284 |
| 5 | 146167 | 122855 |
| 6 | 164349 | 147426 |
| 7 | 182531 | 171997 |
| 8 | 200713 | 196568 |
| 9 | 218895 | 221139 |
| 10 | 237077 | 245710 |
In this model, the 9th incremental update would be our break-even point. If we simplify these models to formulae:
Non-Incremental: 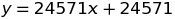
Incremental: 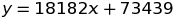
and then find the intersection of these two lines ( ), we’d see that the actual overlap would be at x=8.648771, or “the 9th incremental update”
), we’d see that the actual overlap would be at x=8.648771, or “the 9th incremental update”
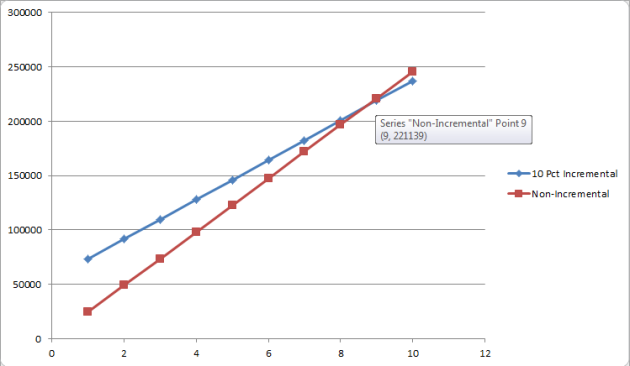
However, bumping the sample rate leads to very different results. The initial update takes 118776 ms. and the average of Partitions 5-9 is 24271.2 ms. Doing the same line-intersection arithmetic, we’d find an intersection at 315.2262, or, we’d recover the time on our 316th statistics update.
So What?
Here are some interesting takeaways from this.
- We can rapidly recover statistics maintenance times with active maintenance that examines partitions
- AutoStats update events preserve the sample rate, and operate only on affected partitions, potentially allowing for faster start-to-finish query execution time when a stats update is necessary
- We can recover statistics maintenence times with a higher sample rate on an incremental statistic over against its non-incremental statistic of a lower sample rate.
- We need to be reasonable with our higher sample rate expectations, because we may never actually recover the time if we sample too high

Pingback: Finding Value in Incremental Statistics, Pt. 2 | Exchange Spill